
فهرست مطالب
آیا تا به حال به دنبال ریشه ی یک پدیده یا چرایی وقوع یک رویداد خاص بوده اید؟ در دنیای پیرامون ما، از دلایل بروز یک بیماری مانند کرونا تا عوامل مؤثر بر موفقیت یک کسب و کار، همه چیز به نوعی با روابط علت و معلولی گره خورده است. کشف روابط علت و معلولی در کار های پژوهشی همواره یکی از پر اهمیت ترین نوع پژوهش بوده و همچنان نیز هست و دلیل اهمیت آن نیز، بررسی تاثیر پدیده ها بر یکدگیر هستند.
یادگیری پژوهش علی (Causal Research) و استفاده از آن در انجام پایان نامه یا انجام مقاله ISI، ارزش کار پژوهشی را بالا میبرد و علت آن نیز در ادامه مقاله برای شما روشن خواهد شد. از سوی دیگر شما با خواندن این مقاله، به طور کامل بر پژوهش علی را صفر تا صد مسلط شده و به صورت کاملا کاربردی آن را خواهید آموخت و به درجه استادی خواهید رسید.
چرا پژوهش علی انقدر مهم است؟
آیا خوردن قهوه باعث افزایش طول عمر می شود؟ آیا کشیدن سیگار باعث کاهش طول عمر می شود؟ آیا سطح درآمد بر روی بزهکاری افراد در جامعه تاثیر دارد؟ دانستن رابطه علت معلولی پدیده ها در پزشکی، سیاست، علوم اجتماعی، کسب و کار و … باعث می شود که افراد بتوانند تصمیم جدی و قاطعانه به نسبت مسائل بگیرند.
به عنوان مثال در پزشکی: اگر داروی X را به افراد دارای بیماری Y تجویز کنیم، بهبودی حاصل می شود یا خیر؟ (کشف درمان)
در سیاست: اگر قانون X برای حل مشکل Y در جامعه کارساز است؟ (سیاست گذاری و قانون)
البته مثال های دیگری هم در ادامه خواهیم زد فقط این را بدانید که وقتی یک پژوهش را انجام می دهیم، معمولاً نتیجه را با چند عدد استاندارد گزارش می کنیم؛ مثل p-value و فاصله اطمینان 95% یا 99%.
p-value خیلی ساده یعنی: اگر “اثری وجود نداشته باشد”، نتیجهای که ما دیدهایم چقدر میتواند اتفاقی باشد.
بعد هم یک خطِ تصمیم میگذاریم که اسمش آلفا است (مثلاً 0.05 یا 0.01) و با آن میسنجیم آیا این نتیجه آن قدر “غیراتفاقی” هست که جدی اش بگیریم یا نه. (منبع)
نکته مهم این است که عددها کمک میکنند بهتر قضاوت کنیم، ولی کیفیت طراحی پژوهش هم خیلی مهم است. در مقاله ای دیگر راجع به روش تحلیل اعداد در مقالات ISI و پژوهش ها بیشتر توضیح خواهیم داد.
فوت کوزه گری تز نویسان: اگر به دنبال ساختن رزومه علمی مناسب تری برای خود هستید، بیشتر به این نوع پژوهش اهمیت بدهید. چرا که در پژوهش های دیگر، هرچند اعتبار علمی به شما می دهند، اما هیچ کدام به اندازه یک “پژوهش علی با طراحی فرضیه های خوب”، سطح و اهمیت بالا ندارند.
روابط علت و معلولی چه روابطی هستند؟
این را می دانیم که «علت» چیزی است که روی «معلول» اثر میگذارد؛ یعنی یک چیز باعث به وقوع پیوستن چیز دیگری میشود. در پژوهش علّی هم دقیقاً دنبال همین هستیم: اینکه بفهمیم آیا واقعاً یک عامل، عاملِ تغییر دهنده عاملِ دیگر بوده است یا نه.
اما این نوع رابطه ها چند شاخص دارند که وقتی کنار هم قرار میگیرند، کمک میکنند ادعای علت و معلولی معنی دار تر و قابل دفاع تر شود. ما زمانی میتوانیم بگوییم یک رابطه علت و معلولی برقرار است که:
- یک سویه باشد: همیشه از علت به معلول می رویم. به عنوان مثال اگر فردی قرص های مسکن مصرف کند، سردرد ایشان کاهش پیدا می کند. رابطه برعکس آن یعنی: «چون سردرد ایشان کاهش پیدا می کند، قرص های مسکن می خورد» صدق نمی کند.
- رابطه زمانی داشته باشد: یعنی اول علت باید اتفاق بیوفتد و سپس معلول رخ بدهد. اگر پدیده ای قبل از X اتفاق بیافتد، آنوقت نمیتوان گفت که X علت آن پدیده است. نهایتا میشود گفت که همزمان اتفاف افتاده اند. به عنوان مثال: ابتدا سنگ پرتاب می شود، سپس شیشه می شکند. اگر اول شیشه بشکند بعد سنگ پرتاب شود، نمی توان گفت که علت شکستن شیشه پرتاب شدن سنگ است.
- قابل تکرار باشد: اگر یک بار به این نتیجه رسیدیم که پرتاب سنگ می تواند در شرایط یکسان باعث شکستن شیشه بشود، باز هم باید بتوانیم به همان نتیجه برسیم. به عبارتی، هر علت باید همان معلول را ایجاد کند.
تمامی این الگوها منطقی هستند و در هر رابطه علت معلولی ترکیبی از این الگو ها یافت می شود.
برای یادگیری پژوهش علی باید یکسری مفاهیم را به صورت پایه ای یاد بگیرید. ما در همین مقاله این مفاهیم را به طور کاربردی همراه با مثال آموزش داده ایم. بعد از یادگیری مفاهیم پایه به سراغ روش نوشتن فرضیه، ویژگی های یک فرضیه خوب، انواع پژوهش علی (آزمایشی، غیر آزمایشی و …) توضیح داده می شوند و شما پس از آن، به چگونگی کار با فرضیه، آزمون ها، سوال پژوهشی و غیره مسلط خواهید بود. مفاهیم پایه ای که به آنها خواهیم پرداخت عبارتند از:
- تعریف پژوهش علی
- انواع متغیر ها
- انواع دامنه ها (جهت ها)
پژوهش علی چیست؟
یک تعریف بسیار دقیق اگر بخواهیم از پژوهش علی داشته باشیم این خواهد بود که بگوییم: “پژوهش علّی نوعی تحقیق است که تلاش میکند رابطه علت و معلولی بین متغیر ها را کشف کند؛ یعنی نشان بدهد که «تغییر در یک متغیر (علت)، واقعاً باعث چه تغییری در متغیر دیگر (معلول) میشود».
اگر فقط بگوییم که این دو متغیر با هم همراه اند(یعنی همزمان با متغیر X متغیر Y هم تغییر می کند.) نام آن پژوهش همبستگی می شود. بررسی این نوع رابطه علت و معلولی بین متغیر ها ممکن است از طریق دستکاری متغیر (در پژوهش های آزمایشی و شبه آزمایشی) یا مقایسه گروه های موجود (در پژوهش علی –مقایسهای) انجام شود.
انواع متغیر ها در پژوهش های علی (علت و معلولی)
البته این متغیر ها صرفا برای پژوهش های علی نیستند و در انواع پژوهش های دیگر نیز مورد استفاده قرار میگیرند اما نکته این است که به عنوان مثال در پژوهش های هبستگی، به علت “پیش بین” یا “مستقل” و معلول را هم “ملاک” یا “وابسته” می گویند.
در یک پژوهش علی استاندارد حداقل این ها متغیر ها را می توانیم داشته باشیم: (مثال های داخل عکس فرضی هستند و بسیاری از متغیر های دیگر می توانند جایگزین شوند.)
-
متغیر مستقل (X): چیزی که به عنوان «علت» یا عامل اثرگذار در نظر گرفته میشود. به طور کلی در مدل ها، اگر فلش ها به متغیر ای وارد نشوند، متغیر مستقل هستند. در شکل زیر می توانید بگویید که کدام متغیر ها مستقل هستند؟
-
متغیر وابسته (Y): نتیجه یا «معلول»؛ چیزی که انتظار داریم تحت تأثیر X تغییر کند. به طور کلی در مدل ها، اگر فلش ها به متغیر ای وارد شوند، متغیر وابسته هستند. حال می توانید بگویید که کدام یک از متغیر ها مستقل هستند؟
-
متغیر میانجی (Mediator): متغیر هایی که “چگونگی” اثر گذاری را نشان میدهند. فرض کنید از تهران میخواهید بروید به اصفهان؛ یک مسیر مستقیم وجود دارد از تهران به اصفهان که ما می توانیم آنرا (DV) نام گذاری کنیم. اما از راه دیگری نیز می توانیم به اصفهان برویم. یعنی می توانیم ابتدا بریم به قزوین و سپس برویم به اصفهان. درک این حالت به مثابه توضیح ساده شده ی متغیر میانجی است.
-
متغیر تعدیل گر (Moderating): شدت یا جهت رابطه بین متغیر مستقل و وابسته را تغییر میدهد. در تصویر زیر، ضریب هوشی تعدیل گر درس خواندن است. این بدین معناست که هوش می تواند بر روی درس خواندن و نمره کنکور در افراد باهوش تاثیر قوی تری داشته باشد و در نتیجه در دریافت نمره خوب در کنکور تاثیر بگذارد.
-
متغیرهای مزاحم (Extraneous Variables): هر متغیری که علاوه بر متغیر مستقل، میتواند روی متغیر وابسته تأثیر بگذارد. مثال: در بررسی تاثیر ورزش بر کاهش وزن، غذای خورده شده پیش از ورزش یا دمای هوا میتواند متغیر مزاحم باشد.
متغیرهای مخدوشکننده (Confounding Variables): نوع خاصی از متغیر مزاحم که هم با متغیر مستقل و هم با متغیر وابسته رابطه دارد و ممکن است رابطه علّی را جعلی یا معکوس نشان دهد.” -
متغیر کنترل (Control): این متغیر نقش کنترل کننده متغیر های مزاحم را دارد. زمانی که صفت ها یا متغیر های خاصی را کنترل می کنی، باعث می شود که داده ها عادی بمانند. به عنوان مثال سهمیه کنکور، تعداد ساعات مطالعه، جنسیت افراد و … از موارد متغیر کنترل هستند.
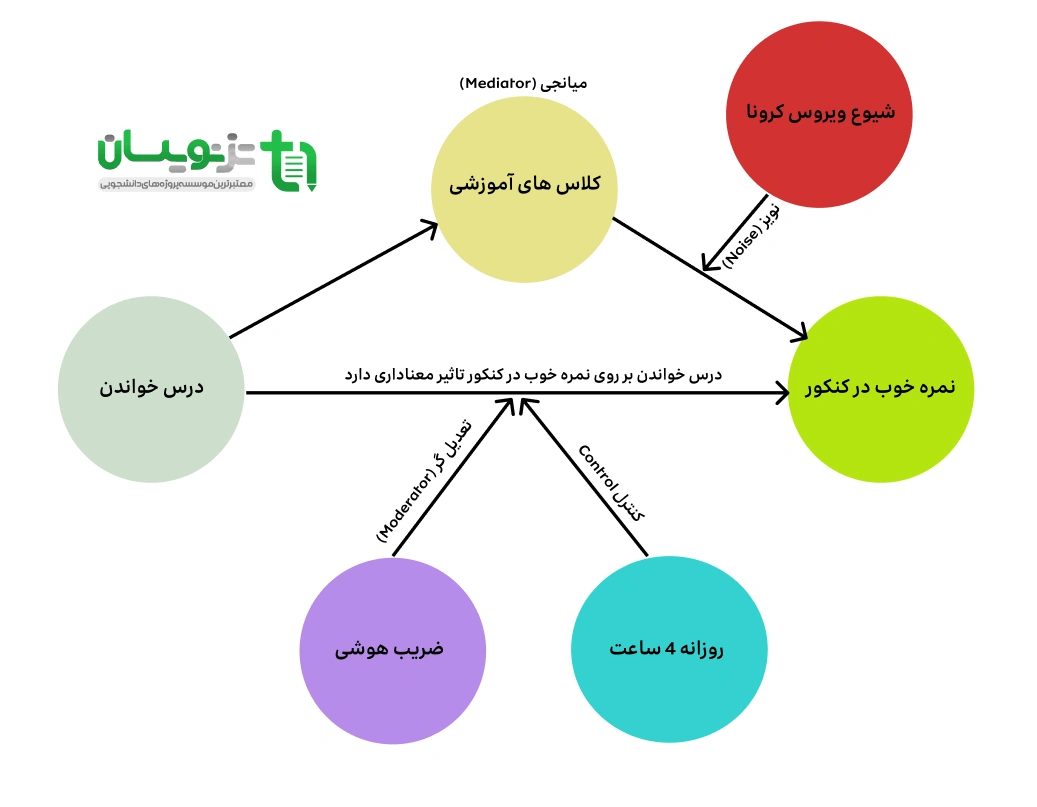
درک این نوع روابط متغیر ها بسیار مهم و حیاتی است و اگر نیاز به راهنمایی بیشتر داشتید می توانید با ما ارتباط بگیرید. برای اطمینان از اینکه آیا به خوبی متوجه نوع روابط شده اید به سوالات زیر مراجعه کنید. (نوع متغیر ها را مشخص کنید!)
مثال 1: فرض کنید یک پژوهشگر میخواهد تأثیر “ساعات مطالعه” را بر “نمرات دانشجویان” بررسی کند.
مثال 2: تصور کنید میخواهید تأثیر “اجرای یک کمپین تبلیغاتی جدید” را بر “افزایش فروش محصول” را اندازه گیری کنید
مثال 3: یک مدرسه دوره “مهارت های مطالعه” برگزار میکند تا ببیند آیا این کار باعث “افزایش نمره کنکور” میشود یا خیر. در این میان، “افزایش ساعات مطالعه منظم در خانه” هم اندازهگیری میشود.
مثال 4: میخواهیم بررسی کنیم “شرکت در کلاس های زبان” چه اثری می تواند بر “پیشرفت در مهارت گفتاری” داشته باشد. پژوهشگر سطح «اعتماد به نفس در صحبت کردن جلوی دیگران» را هم ثبت میکند.
مثال 5: پژوهشگری میخواهد بداند “شرکت در اردو های علمی” چه اثری بر “علاقه به ادامه تحصیل در رشته های علوم تجربی” دارد. او همزمان “جنسیت” و هم “پایه تحصیلی” را ثابت نگه می دارد. (فقط دانش آموزان دختر پایه یازدهم).
انواع دامنه ها در پژوهش علی
ما هنگام مشخص کردن فرضیه ها دو نوع رویکرد داریم. رویکرد اول این هست که بگوییم متغیر X بر روی متغیر Y تاثیر مثبت/ منفی دارد. به این نوع رویکرد فرضیه جهت دار (تک دامنه) می گوییم.
فرضیه جهت دار (تک دامنه)
در فرضیه جهت دار، پژوهشگر علاوه بر اینکه میگوید بین دو متغیر رابطه وجود دارد، حدس میزند این رابطه دقیقاً در چه جهتی است؛ یعنی انتظار می رود که متغیر “وابسته” افزایش پیدا کند یا کاهش؛ مثبت باشد و یا منفی!
به عبارت دیگر، در این نوع فرضیه مشخص میکنیم که:
- رابطه مثبت: هرچه X بیشتر شود، Y هم بیشتر میشود.
- رابطه منفی: هرچه X بیشتر شود، Y کمتر میشود.
با چند نمونه می توانیم خیلی راحت تر این مبحث را پشت سر گذاشته و به سراغ فرضیه های دو دامنه برویم:
- «هرچه ساعات مطالعه برای کنکور بیشتر باشد، نمره آزمون سراسری بالاتر میرود.»
- «افزایش استفاده از شبکههای اجتماعی قبل از خواب باعث کاهش کیفیت خواب نوجوانان میشود.»
- «هرچه تعداد جلسات تمرین ورزشی منظم بیشتر شود، درصد چربی بدن کاهش مییابد.»
در زبان آمار، وقتی فرضیه جهت دارد معمولاً از آزمون های یک دامنه (one-tailed) استفاده می شود، چون فقط یک سمت تغییر مهم است. مثلا می توان آزمون t تک نمونه ای، دو نمونه مستقل یا زوجی و یا حتی آزمون نسبت ها z استفاده کرد که هر کدام توضیح مربوط به خودشان را دارند ولی این موارد را در ذهن بسپارید.
فرضیه بی جهت ( دو دامنه)
اگر بدون مشخص کردن نوع تاثیر صرفا در فرضیه بنویسیم که “متغیر X بر روی متغیر Y تاثیر گذار است”، این نوع فرضیه دو دامنه است. به عنوان مثال: “بین میزان استفاده از کلاسهای آنلاین و نمره کنکور رابطه معناداری وجود دارد.” یک فرضیه دو دامنه است.
اگر در مقالات ISI هم خوانده باشید به عنوان مثال به زبان انگلیسی می نویسند:
We hypothesized that there would be a significant relationship between study time and exam performance
نکته بسیار مهم:
وقتی پژوهشگر درباره ادبیات موضوع و نتایج پژوهش های قبلی اطلاعات کافی دارد و یک جهت مشخص را انتظار دارد، اغلب از فرضیه جهت دار استفاده میکند. اما اگر مطمئن نباشد رابطه مثبت است یا منفی، یا بخواهد خودش را به یک جهت خاص محدود نکند، فرضیه بدون جهت مینویسد.
انواع پژوهش علی
ما برای اینکه بتوانیم به سوالات پژوهش جواب درستی بدهیم یا بهتر است بگویم برای اینکه بتوانیم به سوالات جواب بهتری بدهیم، نیاز است که با انواع پژوهش آشنا شویم. البته این انواع پژوهش صرفا برای پژوهش علی نیستند و ما در همبستگی و تفاوتی نیز از بعضی از این پژوهش ها استفاده می کنند.
برای درک بهتر مفهوم بهتر است بگویم که ما برای جمع آوری اطلاعات و به طور کلی بررسی نمونه آماری، از این راه ها می توانیم استفاده کنیم. به دیگر کلام، پژوهش علی مقصد است اما موارد زیر، مسیر رسیدن به آن هستند.
ما می توانیم بر اساس میزان کنترلی که در تغییر متغیر ها داریم، پژوهش علی را به سه دسته تقسیم بندی کنیم و شما می توانید برای انجام پژوهش خود از یکی از این سه روش استفاده کنید.
پژوهش آزمایشی واقعی – حقیقی (True Experimental Research)
پژوهش علی آزمایشی بالاترین اعتبار علمی را دارد که ما در آن توانایی دستکاری متغیر مستقل را داریم در صورتی که بتوانید از این روش در مقالات ISI خود استفاده کنید با درصد موفقیت بیشتری در چاپ در ژورنال های Q1 و Q2 موفق می شوید. اما پژوهش آزمایشی واقعی یعنی چه؟ به طور ساده و خلاصه، این نوع پژوهش با تغییر متغیر ها، تصادفی سازی و کنترل گروه ها می توانیم به نتایج دقیق تری دست پیدا کنیم. (احتمالات 95 درصد و 99 درصد)
یعنی پس از انجام پژوهش با این روش می توانیم با احتمال 99 درصد بگوییم که متغیر X بر روی Y اثر دارد. حال چطوری باید این روش را پیاده سازی کرد؟ مثال میزنیم:
فرض کنیم یک پژوهشگر میخواهد ببیند آیا داروی جدید X باعث کاهش فشار خون میشود یا خیر. 100 بیمار را بهصورت تصادفی به دو گروه 50 نفره تقسیم میکند:
- گروه آزمایش: داروی جدید میگیرند.
- گروه کنترل: دارونما (placebo) میگیرند.
بعد از 3 ماه، فشار خون هر دو گروه را مقایسه میکند. اگر گروه آزمایش بهبود معناداری داشته باشد، میتواند بگوید «دارو بر روی کاهش فشار خون تاثیر دارد».
یا فرض کنیم که یک پژوهشگر دیگر میخواهد تاثیر روش تدریس را بر روی یادگیری بهتر ریاضی در دانش آموزان بسنجد برای اینکه بداند چه روش تدریسی می تواند نمره ریاضی دانش آموزان را بهبود دهد. برای این کار 60 دانش آموز را به صورت کاملا تصادفی انتخاب کرده و به دو گروه تقسیم می کنند.
- گروه آزمایش: با روش های فعال (کار گروهی، حل مسئله و …) درس میخوانند.
- گروه کنترل: با روش سنتی (سخنرانی) درس میخوانند
هر دو گروه با یک معلم، در یک کلاس، در ساعات یکسان درس میخوانند. بعد از یک ترم، نمره ها را مقایسه شده و نتیجه توضیح داده می شود.
نقاط قوت و محدودیت های پژوهش آزمایشی
هر چیزی نقاط قوت و ضعف خودش را دارد و پژوهش علی آزمایشی نیز از این قاعده مستثنا نیست. این پژوهش قابلیت کنترل کامل متغیر های مزاحم را به ما میدهد و البته شاید اعتبار علمی بالایی داشته و رزومه آکادمیک خوبی برای پژوهشگر یا دانشجو باشد اما تمام ماجرا این موارد نیستند.
پژوهش آزمایشی زمان و هزینه زیادی نیاز دارد و به راحتی قابل انجام نیست. برای بسیاری از آزمایش ها محدودیت های اخلاقی وجود دارد و ما نمیتوانیم به عنوان مثال کسی را بیمار کنیم یا به ایشان آسیب بزنیم تا بعد پژوهشی انجام دهیم. از سوی دیگر، در محیط های واقعی انجام این پژوهش سخت است. فرض کنید همان مثال دوم یعنی تاثیر نوع تدریس ریاضی بر نمره را میخواهید پیاده سازی کنید. ممکن است مدیر مدرسه بگوید که ما کلاس ها را از ابتدای سال تقسیم بندی کرده ایم و اجازه ندهد تا دانش آموزان را تصادفی جدا کنید یا حتی ممکن است والدین بگویند که چرا فرزند من باید روش تدریس متفاوتی داشته باشد.
اگر نتوانستید شرایط را جور کنید، در این صورت چه کاری انجام می دهید؟ دو کلاس در همان مقطع را که از قبل دسته بندی شده اند را انتخاب کرده به عنوان مثال: “کلاس دهم 1” و “کلاس دهم 2” و بعد روی آنها آزمایش را انجام می دهید. که البته در این صورت دیگر این پژوهش آزمایشی واقعی نبوده و تبدیل به پژوهش شبه آزمایشی می شود.
پژوهش شبه آزمایشی (Quasi-Experimental Research)
در پژوهش شبه آزمایشی ما همچنان می توانیم متغیر ها را دستکاری کنیم ولی نمی توانیم تصادفی سازی کنیم و باید به سراغ گروه های از پیش تعیین شده برویم. این نوع پژوهش ها اعتبار علمی کمتری دارند ولی نتایج به واقعیت نزدیک ترند. زمانی که هزینه انجام پژوهش علی آزمایشی بسیار سنگین و گران است و یا توانایی تقسیم تصادفی افراد را ندارید، می توانید از این روش استفاده کنید.
برگردیم به مثال مدرسه: فرض کنید یک مدرسه دو کلاس دهم دارد و شما نمی توانید دانشآموزان را جابهجا کنید (چون والدین اجازه نمیدهند یا مدیریت مخالف است). پس تصمیم میگیرید:
- کلاس A: با روش تدریس جدید (یادگیری مبتنی بر پروژه)
- کلاس B: با روش تدریس سنتی
بعد از یک ترم، نمره های دو کلاس را مقایسه میکنید. اگر کلاس A بهتر باشد، میتوانید بگویید «احتمالاً روش جدید مؤثرتر بوده»، اما نمیتوانید کاملاً مطمئن باشید (چون شاید کلاس A از قبل باهوشتر بودهاند).
نا گفته نماند که خود طرح شبه آزمایشی نیز سه حالت مختلف دارد:
طرح گروه های غیر معادل (NEGD):
دو گروه که از قبل وجود داشته اند و دسته بندی شده اند را انتخاب می کنید. یکی از آن ها را دستکاری کرده و دیگری را ثابت نگه می دارید. در نهایت هر دو گروه را با یکدیگر مقایسه کرده و نتایج را گزارش می کنید. مثال: فرض کنید که یک شرکت دو واحد دارد (فروش و پشتیبانی) که از بین این دو واحد، بخش فروش برنامه آموزشی می بیند ولی واحد پشتیبانی هیچ دوره ای دریافت نمی کند. بعد از 6 ماه عملکرد هر دو واحد را بررسی می کنیم.
طرح ناپیوستگی رگرسیون (RDD):
بر اساس یک معیار، آستانه یا امتیاز یک گروه رو به دو قسمت تقسیم می کنیم. به عنوان مثال دانش آموزانی که بالای 10 گرفته اند و دانش آموزانی که نمره آنها زیر 10 شده است. شما می توانید افرادی که نزدیک به این خط برش قرار دارند را مورد بررسی قرار دهید و چون نمرات تفاوت خیلی کم و در حد یکی دو نمره دارند، می توانید با مداخله نتیجه ای مانند پژوهش آزمایشی بگیرید. به عنوان مثال افرادی که زیر 10 قرار دارند را کلاس تقویتی بفرستید و بالای 10 گرفته اند را بدون مداخله باقی بگذارید.
منطق آن نیز این است که اگر بعد از مداخله، تفاوت معناداری بین این دو گروه ببینید، میتوانید بگویید: «احتمالاً به خاطر مداخله بوده، چون قبل از مداخله تقریباً یکسان بودند».
این شبیه به تصادفی سازی محلی است (البته نه خود تصادفی ولی رویکردی نزدیک به آن دارد.)
بگذارید یک مثال کامل بزنیم تا به طور کامل با این نوع پژوهش شبه آزمایشی آشنا شوید.:
- همه دانش آموزان یک آزمون میدهند و نمره میگیرند.
- ما می گوییم که «هرکس نمره کمتر از ۱۰ بگیرد، باید کلاس تقویتی ببیند» پس:
- گروه مداخله: دانشآموزانی که نمره 9، 8، 7، 6 و… گرفتهاند → کلاس تقویتی میبینند
- گروه کنترل: دانشآموزانی که نمره 10، 11، 12، 13 و… گرفتهاند → کلاس تقویتی نمیبینند
حالا محقق فقط روی دانشآموزانی که خیلی نزدیک به ۱۰ هستند تمرکز میکند:
- کسانی که 9 یا 9.5 گرفتند (درست زیر آستانه)
- کسانی که 10یا 10.5 گرفتند (درست بالای آستانه)
این دو گروه از نظر توانایی تقریباً یکسان هستند (یکی 9 گرفته، یکی 10 گرفته؛ تفاوت خیلی کمی دارند)، اما یکی کلاس تقویتی شرکت کرده و دیگری هیچگونه کلاسی شرکت نکرده.
بعد از یک ترم، نمره نهایی هر دو گروه را میسنجید:
- اگر کسانی که کلاس تقویتی دیده اند نمره بیشتری نسبت به کسانی که ندیدهاند گرفتند پس کلاس تقویتی تاثیر گذار بوده است.
- اگر تفاوت معناداری نباشد پس می توان گفت که کلاس تقویتی بی اثر بوده
نکات مهم:
باید با منطق آستانه ها را انتخاب کنید و تنها افراد نزدیک به آستانه را مورد بررسی قرار دهید. چرا که ممکن است کسی که از آستانه فاصله داشته باشند، نتایج پژوهش بر روی آن به علت وجود متغیر های تعدیل گر (ضریب هوش و …) دچار مشکل شود. همچنین باید تعداد داده های بسیار زیاد تری داشته باشید چرا که احتمال بسیار کمی وجود دارد تا بتوانیم افراد زیادی را پیدا کنید که دقیقا نزدیک به آستانه قرار داشته باشند مگر اینکه نمونه آماری ما گسترده تر باشد. (چند نفر از یک کلاس 30 نفره، ممکن است نمره 10.5 یا 9.5 بگیرند؟ باید نمونه بزرگتری داشته باشید)
اگر قبل از مداخله از هر دو کلاس «پیش آزمون» بگیری، ادعای تو قوی تر میشود
۳. آزمایش های طبیعی:
یک رویداد خارجی (مثل تغییر قانون، بلای طبیعی، سیاست جدید) به صورت طبیعی افراد را تقسیم میکند. مثال: یک استان قانون جدید را اجرا میکند، استان دیگر نه؛ شما اثرش را مقایسه میکنید. یا یک زلزله در یک شهر رخ می دهد و شما اثرات آن را مورد بررسی قرار می دهید.
به عنوان مثال زلزله بم در سال 1382 رخ داد. می توانیم بیایم و بررسی کنیم که مردم شهر بم و افراد شهر مشابه دیگر (که زلزله ندیدند) از نظر سلامت روان چه تفاوتی دارند؟ در اینجا، زلزله «رویداد طبیعی» است که محقق آن را دستکاری نکرده، بلکه فقط از آن برای مقایسه استفاده میکند.”
پژوهش علی – مقایسهای / پس رویدادی (Causal-Comparative / Ex Post Facto)
در پژوهش علی مقایسه ای ما نه می توانیم متغیر های مستقل را دستکاری کنیم و نه می توانیم تصادفی سازی انجام دهیم. در این نوع پژوهش ما تنها می توانیم دو گروه را با یکدیگر مقایسه کنیم
- ویژگیهای کلیدی:
- عدم دستکاری متغیر مستقل: پژوهشگر نمیتواند متغیر مستقل را تغییر دهد؛ بلکه گروههایی را انتخاب میکند که به صورت طبیعی در معرض سطوح مختلف متغیر مستقل قرار گرفتهاند.
- عدم تصادفیسازی: از آنجا که متغیر مستقل از قبل وجود داشته، امکان تصادفیسازی وجود ندارد. این موضوع، مهمترین محدودیت این نوع پژوهش در اثبات قطعی علیت است.
- مقایسه گروههای موجود: گروههایی که از نظر متغیر مستقل با هم تفاوت دارند، از نظر متغیر وابسته مقایسه میشوند.
- مثال کاربردی:
- در روانشناسی/جامعهشناسی: بررسی تأثیر “طلاق والدین” (متغیر مستقل که در گذشته رخ داده) بر “افسردگی کودکان” (متغیر وابسته). پژوهشگر نمیتواند والدین را به صورت تصادفی مجبور به طلاق کند. او کودکانی را که والدینشان طلاق گرفتهاند، با کودکانی که والدینشان با هم زندگی میکنند، مقایسه میکند.
- در اقتصاد: بررسی تأثیر “سیاستهای مالی دولت در دهه گذشته” (متغیر مستقل) بر “نرخ تورم کنونی” (متغیر وابسته). این سیاستها در گذشته اجرا شدهاند و نمیتوان آنها را دستکاری کرد.
| معیار | آزمایشی واقعی | شبهآزمایشی | علی–مقایسهای |
|---|---|---|---|
| دستکاری متغیر مستقل | بله | بله | خیر (از قبل وجود دارد) |
| تصادفیسازی | بله (تصادفی سازی) | خیر (از قبل وجود دارد) | خیر |
| گروه کنترل | بله (گروهی که مداخله نمیبیند) | معمولاً بله | بله (گروه مقایسه) |
| کنترل شرایط | کامل (همه چیز تحت کنترل) | محدود (بعضی چیزها کنترل نیست) | خیلی محدود |
| اعتبار داخلی | بالا (۹۵-۹۹٪) | متوسط (۷۰-۸۵٪) | پایین (۵۰-۶۵٪) |
| اعتبار بیرونی | پایینتر (نتایج آزمایشگاهی) | بالاتر (نتایج در دنیای واقعی) | بالا (نتایج واقعیتر) |
| هزینه و زمان | زیاد | متوسط | کم |
| محیط اجرا | آزمایشگاه یا میدان | میدانی (مدرسه، شرکت، بیمارستان) | میدانی |
| پذیرش در مجلات Q1 | بسیار بالا | متوسط تا بالا | متوسط |
| مثال | آزمون دارو با قرعهکشی | کلاسهای مختلف با روشهای مختلف | مقایسه قبولشده/افتاده |
روش نوشتن فرضیه (به زبان ساده و کاربردی)
فرضیه یعنی «حدسِ قابل آزمون»؛ این یک جمله ای است که خیلی روشن به مخاطب و خوانندگان مقاله یا پایان نامه شما میگوید چه چیزی روی چه چیزی اثر دارد (یا ندارد)، و همین جمله قرار است با داده در پژوهش شما بررسی شود.
برای نوشتن فرضیه، این 5 قدم را برو:
- اول سؤال را دقیق کن: «آیا X روی Y اثر دارد؟» (مثلاً: آیا ساعات مطالعه روی نمره اثر دارد؟)
- متغیرها را عملیاتی کن: یعنی بگو X و Y را دقیقاً چطور اندازه میگیری (ساعات مطالعه = چند ساعت در روز؟ نمره = نمره امتحان پایانترم یا آزمون کلاسی؟).
- جامعه/گروه را مشخص کن: «دانشآموزان پایه دهم شهر …» یا «دانشآموزان یک دبیرستان».
- نوع فرضیه را انتخاب کن: (بالاتر توضیح داده شده است)
-
- فرضیه جهتدار: اگر از قبل میدانی اثر مثبت است یا منفی (مثلاً «هرچه X بیشتر، Y بیشتر»).
- فرضیه بیجهت: اگر فقط میدانی «اثر هست/نیست» ولی جهت را مطمئن نیستی.
در نهایت می توانید که خیلی ساده جملات را بازنویسی کرده و به صورت تمیز تری بنویسید.
قالبهای آماده
- جهتدار مثبت: «هرچه X بیشتر شود، Y بیشتر میشود.»
- جهتدار منفی: «هرچه X بیشتر شود، Y کمتر میشود.»
- بیجهت: «بین X و Y رابطه معناداری وجود دارد.»
- مقایسهای: «میانگین Y در گروه A با گروه B تفاوت دارد.»
فوت کوزهگری: اگر فرضیه ات طوری نوشته شود که هر کسی بتواند با یک آزمون آن را اندازه بگیرد یعنی فرضیه درست و خوبی نوشته شده است.

اولین نفری باشید که دیدگاه میدهد
دیدگاه خود را بنویسید
نظر شما برای ما ارزشمند است. لطفاً با احترام و رعایت قوانین، دیدگاه خود را ارسال کنید.